Actualité
,
Lecture
,
Ressources
Visualiser la guerre de Sécession en data design
Par Jean-Marie Lagnel, publié le 18 juin 2024
Jean-Marie Lagnel est un data designer passionné mais il également auteur et formateur chez Swash. Récemment, il a « data designé » un article sur la guerre de Sécession pour le mook N°4 intitulé de la guerre qui est sorti en mai 2024 chez Perrin. À cette occasion, il prend la plume pour expliquer son cheminement et reposer quelques fondamentaux sur l’infographie, la composition, le data art, la mise en pages ou la data visualisation. Une véritable masterclass avec plein de conseils à « bookmarker ».
Le projet
Partons du principe que le data designer est le premier lecteur. Pour être en mesure de proposer une mise en scène visuelle adaptée, juste et fidèle au contenu, il doit parfaitement comprendre la matière première, avec de nombreuses données qualitatives et quantitatives, fournie par l’historien. Ici, pour les données historiques, nous avons Vincent Bernard, un spécialiste français de la guerre de Sécession. Pour le traitement en data design, votre serviteur ☺️.
Contexte historique
Le poids économique et démographique du Nord conduit à l’élection d’un président, Abraham Lincoln, appartenant à un parti ouvertement abolitionniste. Un motif suffisant de rupture pour les élites du Sud qui, en quelques mois, provoquent la sécession de 11 États esclavagistes sur 15. C’est le début de la guerre de Sécession (1861-1865).
La première guerre moderne ?
Des dizaines de milliers de brevets d’invention ont été déposés pendant la guerre. C’est aussi le temps des premiers cuirassés (aux formes improbables), du premier sous-marin, des toutes premières mitrailleuses, des fusils à canon rayé apportant une précision inconnue jusqu’alors, sans oublier l’usage du chemin de fer et du télégraphe. Nous disposons aussi de données sur les effectifs du Nord et du Sud, sur le budget de la guerre, sur la dette publique et l’inflation. Les chiffres montrent également le coût humain colossal en nombre de soldats américains morts, supérieur à celui des deux guerres mondiales réunies. Bref, beaucoup de data à scénariser.
Des cartes, mais pas seulement
Varier les types de visualisation est ici essentiel car le thème de la guerre de Sécession impose beaucoup de représentations cartographiques. Je dis souvent aux étudiants ou professionnels que j’accompagne qu’une carte peut être remplacée par un graphique et inversement. Il faut bien comprendre que la carte va apporter une vision globale et géolocalisée de l’information, mais que le graphique va permettre une lecture plus détaillée des chiffres et du texte. Il s’agit donc d’une complémentarité d’informations et pas d’une redondance lorsqu’on combine carte et graphique sur le même sujet.

Des informations qui sautent aux yeux une fois visualisées
Les graphes mettent en évidence ce qui est caché dans un tableau de chiffres. Connaissez-vous la première cause de décès du conflit ? Ce sont les maladies ! En particulier la fièvre typhoïde, loin devant les maladies pulmonaires et autres… Et seulement ensuite le nombre de tués au combat. Il faut penser au rythme graphique et enchaîner des cartes géographiques ou géométriques (cartogrammes), des diagrammes différents pour rendre le résultat engageant et éviter de lasser le lecteur avec des représentations trop similaires sur les doubles pages. Contrairement aux idées reçues, une fois spatialisées sur une carte des États-Unis, les données de 1860 montrent au lecteur que les États du Sud n’étaient pas les seuls États esclavagistes, loin de là. Un autre exemple avec la carte des résultats de l’élection présidentielle de 1860, qui révèle clairement, de façon presque prémonitoire, deux blocs qui vont bientôt s’affronter.

Repérer les erreurs classiques
Vous pouvez avoir une idée de mise en scène ou de forme de graphe en découvrant le contenu, mais c’est seulement en testant des possibilités de visualisation que vous faites réellement connaissance avec les données et que vous vous rendez compte de ce qui fonctionne ou pas. Et ne croyez pas qu’avoir les données et les outils suffit ! Il faut presque toujours, en tout cas à partir d’un certain niveau de données, utiliser un tableur pour réorganiser les informations afin d’explorer des types de formes qui ne seront pas accessibles avec la structure de départ du jeu de données. C’est-à-dire qu’il faut souvent faire « pivoter » les données. Un exemple : si vous avez une colonne qui regroupe plusieurs années, la forme graphique, qui sera peut-être la bonne, pourra nécessiter, pour être réalisée, d’utiliser une structure différente avec une année par colonne ! Cela peut être une manipulation simple, comme une transposition ligne/colonne, un TCD (tableau croisé dynamique), ou alors il faudra passer par le code (Python). L’intelligence artificielle (ChatGPT, Magic Write, Copilot ou Gemini) est utile pour gagner du temps en manipulation, surtout si vous n’êtes pas à l’aise avec les tableurs ou si, comme moi, vous ne codez pas. Mais attention à la qualité et à la précision du prompt, et n’oubliez pas que le même prompt donne des résultats différents selon l’entraînement des IA, ce qui peut être assez déroutant en pratique…
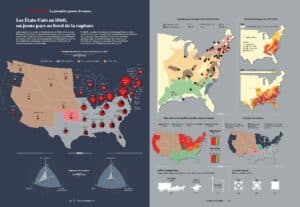
Une autre erreur récurrente est de représenter les valeurs brutes, car elles sont rarement comparables. Il y avait aux États-Unis 17,5 % d’esclaves en 1790 et « seulement » 13 % en 1860. Est-ce que l’esclavage diminue pour autant ? En réalité, la diffusion de l’esclavage pendant cette période doit être recontextualisée par rapport au nombre d’habitants. Car il y avait seulement 4 millions d’habitants en 1790 (dont 700 000 esclaves), mais la population explose à 31 millions d’habitants en 1860 (dont 4 millions d’esclaves) !
L’importance de la contextualisation visuelle
Dans ce projet, la contextualisation visuelle est nécessaire pour faciliter la lecture et faire comprendre le thème de la guerre de Sécession au lecteur du premier coup d’œil. La représentation figurative ou descriptive est par exemple ici de circonstance, notamment pour les uniformes et les armes du conflit, car elles ont une iconographie très forte et sont facilement identifiables par le lecteur… qui aura peut-être lu les BD Blueberry, dessinées par Jean Giraud (Mœbius), ou vu un des nombreux films sur la « Civil War ». C’est aussi le cas avec le portrait d’Abraham Lincoln, que j’ai choisi pour l’ouverture du dossier et que j’ai réalisé en partie avec une IA générative (Midjourney) pour gagner du temps, mais sans faire de concession sur la cohérence du style graphique.

Il y a aussi de fausses idées reçues à propos du fameux drapeau confédéré (celui avec la croix rouge) repris aujourd’hui par les extrémistes républicains pro-Trump. Je suis évidemment tombé dans le piège et avais dessiné le mauvais drapeau ! Je cite Vincent Bernard : « Le « Battle Flag », si souvent représenté aujourd’hui, est en réalité un étendard de guerre et pas un drapeau politique. » J’ai donc suivi les remarques de l’historien et modifié le dessin du drapeau des confédérés pour un « Stars and Bars » à 13 étoiles, certes beaucoup moins impactant visuellement, mais tellement plus juste sur le plan historique. C’est donc une approche graphique figurative de l’information, qui respecte les références réelles des visuels historiques et ne laisse aucune place à l’interprétation personnelle du data designer, qui est ici appliquée dans ce type de projet.
Infographie, data art, data storytelling ou data design ?
Une autre possibilité est la représentation abstraite de la donnée. Comme le propose, par exemple, la data designeuse Federica Fragapane, qui dessine presque toujours sur Illustrator ses propres formes originales, souvent organiques, et dont le sujet ne peut être compris qu’une fois le titre lu. Seulement 10 % de son travail contient des formes « classiques » de graphes, comme des dendrogrammes circulaires ou des diagrammes de Voronoï. La légende est un vrai « mode d’emploi » de sa création, qui est souvent très dense et complexe, au risque de dissuader le lecteur dont la « graphicité » (capacité du lecteur à décrypter les informations sous forme de graphe, cf. Alberto Cairo) sera mise à rude épreuve. Cette démarche se rapproche plus du data art, où l’esthétique prime sur l’information. Elle est à mon avis plus adaptée à une scénographie qu’à ce projet sur la guerre de Sécession. D’ailleurs, ce n’est pas un hasard si, en 2023, le MoMA de New York lui a acheté trois de ces réalisations pour sa collection permanente… Comme quoi la frontière entre design d’information et art peut être mince. Dans ce projet, j’ai créé une forme originale (saurez-vous la trouver ?) pour représenter le plus clairement possible un grand nombre de données et de sous-indicateurs sur une pleine page.
La contrainte du format print
Les outils utilisés dans ce projet sont multiples : un tableur pour organiser les données, Adobe Illustrator pour une partie des visualisations, Flourish Studio pour une autre en complément, un peu d’IA générative et Adobe InDesign pour la mise en pages finale. L’enjeu est « d’habiller » les données brutes en trouvant le bon équilibre entre transmission d’informations et rendu visuel esthétique, mais aussi en gérant l’espace disponible. Une donnée pourra être minimisée ou au contraire mise en avant de façon exagérée selon sa forme graphique. Les infographies descriptives (comme celle du système de recrutement de l’Union), les graphes, les cartes et le texte doivent cohabiter dans la composition et trouver leur juste place. Si une visualisation comporte plusieurs indicateurs, elle devra être suffisamment grande pour être lisible. Faire rentrer toutes les informations dans un format imposé n’est jamais facile (attention à la gestion du pli des doubles pages…) et demande une bonne exploration des types de diagramme possibles.
Il convient également de faire des choix assumés dans les principes de composition des doubles pages. Évidemment, les notions de mise en pages, comme la grille et la gestion de la typographie, pour n’en citer que deux, doivent être maîtrisées. Pour moi, réfléchir à la hiérarchie de l’information dans son ensemble est ce qu’il y a de plus chronophage. Le sens de lecture, la logique de présentation de l’ensemble, sont des questions à trancher. C’est à ce niveau de la conception que la valeur ajoutée du data designer se déploie réellement, l’exécution n’est plus qu’une formalité technique. Enfin cela demande quelques années de pratique, bien entendu…
La bonne nouvelle : il y a plein de formations data design chez Swash, on en parle bientôt ensemble ?
Bibliographie
De la Guerre. Mook 1, 2, 3 et 4, 2021-2024, Jean Lopez et collectif, Perrin.
Infographie de la Seconde Guerre mondiale, 2018, Nicolas Guillerat, Jean Lopez, Nicolas Aubin et Vincent Bernard, Perrin
Infographie de la Rome antique, 2020, Nicolas Guillerat, John Scheid et Milan Melocco, Passés composés
La Révolution française en infographie, 2021, Julien Peltier et Jean-Clément Martin, Passés composés
Infographie de l’Empire napoléonien, 2023, Nicolas Guillerat, Vincent Haegele et Frédéric Bey, Passés composés
Auteur
Après des études en arts graphiques, Jean-Marie Lagnel travaille chez Ubisoft puis au service Infographie de Libération et dans différentes agences (Idé, Wag…).
Il crée ensuite le collectif Studio V2 qu’il transforme rapidement en agence spécialisée dans le data design. En 2020, il revend ses parts et prend un statut de data designer indépendant.
En parallèle de ses activités graphiques, il accompagne des professionnels (graphistes, communicants, journalistes…) et des étudiants (à Sciences Po, au CFJ, au CNAM) dans le développement de leurs compétences en data design. Il est également l’auteur du « Manuel de data visualisation » aux éditions Dunod.

À lire sur notre blog
La newsletter de Swash
Tous les mois nous envoyons une sélection d'articles, nos inspirations et nos envies de sortie. Si vous souhaitez être tenu au courant de notre actualité, il suffit de vous inscrire juste ici !
Nous vous recommandons ces formations
Culture data design : environnement de production et tendances
Intégrer les bonnes pratiques pour (re)présenter visuellement des données
Initiation
2 jours
|
14 heures
Illustrator et data design : sublimez vos données
Se perfectionner sur Illustrator et découvrir des outils complémentaires pour (re)présenter visuellement des datas
Approfondissement
2 jours
|
14 heures
Data storytelling : quand vos données racontent une histoire
Informer, communiquer, séduire... Conjuguer data visualisation et storytelling pour faciliter la diffusion de données
Initiation
1 journée
|